【インタビュー】
オーバシュート・ゼロを実現した強化学習によるプラント制御
横河電機㈱ プロダクト本部コントロールセンターマネージャー 後藤 宏紹氏に聞いた
横河電機がNTTドコモと共同でプラントをリモート制御する実証実験を始めた。このリモート制御には5G通信、AIが活用されている。また、ここでのAI活用には、新しくプラント制御に最適な強化学習を用いたAIを開発し、適用している。
そこで、新しく開発されたAIとはどのようなものか、その対象としたプラントは、5Gによりリモート制御する理由などを聞いた。
―まず初めに、横河電機がNTTドコモとプラントプロセスの制御に、共同実験をする理由からお聞きしたい。
後藤:わが社では、今後のwithコロナの中で、プラントのシステムをリモートで自律制御することが方向性と見ています。しかし、プラントをリモート制御するには、従来の無線通信では遅延が発生するため、技術的課題がありました。そこで、高速・大容量・低遅延の特徴を持つドコモの5Gにより、共同実験という形で実証に入りました。 ―プロセス制御では、5Gでよく言われる高速・大容量は必要ないのじゃありませんか? 後藤:5Gがすごく速いからという理由で5Gを採っているわけではないのです。では何かというと、5Gの低遅延性に私たちは注目しています。低遅延というものが制御にものすごく関係してくると考えています。例えば4Gでつないだ時に、4Gで1秒の制御をやった場合、返ってくる通信が遅いのではなくて遅延が発生して、1.2秒1.3秒になったりする。実際にはコンマ3秒コンマ4秒は大きな数字ではないですが、1秒の周期で動かしているという状況の中では大きなズレが発生してしまう。それで低遅延性を持つ5Gで制御周期を乱さない方向に持っていきたい。それが5Gを使っているというのが現状です。 ―さらに重ねて質問ですが。そもそもプロセス制御をリモートでやる必要がありますか。 後藤:リモートで制御をするということが本命ではなく、リモートにすることで可能性が広がるということです。どのような可能性かというと、今は三段水槽をAI制御しているわけですが、これをユーザが行うためには膨大な演算処理ができる高度なCPUを備えたPCをユーザ現場に置かなければならない。リモート、つまりクラウドの形をとれば、ユーザ側の設備をそのまま維持した状態で、コントローラに通信モジュールさえつければ制御AIから指示ができる環境になる。リモートで三段水槽の制御性能を上げるということではなく、ユーザがAI制御を簡単につかえるようにすることが狙いです。 ―ところで、リモート制御の対象になったプロセスは三段水槽と聞いております。それより前に横河電機では奈良先端科学技術大と共同で、この三段水槽におけるAI適用に新しい強化学習のアルゴリズムを開発した。三段水槽に適用した成果は。 後藤:ここで使われた三段水槽は下段の水槽の水位制御を行うことを目的とした、制御トレーニング実験装置の一種です(写真1)。 バルブを開閉することで水槽3へ流れる流量を調整し、水槽1の水位を制御することを目標としています。水槽3に対するバルブ開閉のアクションが水槽1の水位に反映されるまでにタイムラグがあるため、マニュアル操作による制御で水槽1の水位を目標値に保つことが難しいシステムです(図1)。 限界感度法を用いてチューニングしたPID制御では、図2のようにオーバーシュートし、目標値の±5%以内とする制定値に入るまでに200秒以上かかっている。しかし強化学習により30回の学習を終えた後のモデルを用いたAI制御では、オーバーシュートがなく(図3)、目標値までなめらかに立ち上がり、制定時間も100秒と半分になりました。 ―ポンプの脈動など外乱への対応はどうでしょう。 後藤:それが外乱の影響はないといえるほど強いのです。強化学習したモデルを使い、図4のように外乱経路を設けて外乱を起こし、最初の実験とは逆に水槽1の水位を上げた状態から実験を行いました。 モデル作成は水槽1の水位を0からスタートさせたのですが、水位を高い状態からスタートさせてもアンダーシュートがありませんでした(図5)。 モデルには水槽1の水位を上げた状態からの学習はさせていなかったのですが、30回の学習過程の中に水槽1の水位が高くなった時がありました。AIはその時のサンプルを利用して制御したと考えられます。つまり学習過程によって外乱発生時にも対応できるモデルを生成できると思われます。 ―すごい機能ですね。ディープラーニングというと、普通、数千回から数万回の学習が必要と言われますが、数十回、いや30回ですか、それだけでここまでできるモデルとなると、将棋の藤井3冠なみですね。 その強化学習のアルゴリズムについて、わかりやすく教えてください。 後藤:新しいアルゴリズムはFKDPP(factorial kernel dynamic policy programming)といいます。奈良先端科学技術大学院大学の強化学習技術KDPPを発展させ、プラントの自動最適化運転に活用可能な強化学習アルゴリズムとして開発したものです。サンプルでも学習が期待できます。
FKDPPは、KDPPをベースにプラントの知見を入れて開発したアルゴリズムです。特徴は、通常100万回以上必要とされる試行錯誤回数が、わずか30回程度であるという点です。これは、AI制御を実用化する上で大きなポイントとなります。 これを適用した3段水槽でのAIによる強化学習成果は、素晴らしい結果を得られたと思っています。しかし実プラントとなると課題は残ります。学習回数をどこまで減らせるか、シミュレータをどう活用するかなど考えていかねばなりません。
(聞き手:編集部/稲橋一彦)

写真 1 三段水槽
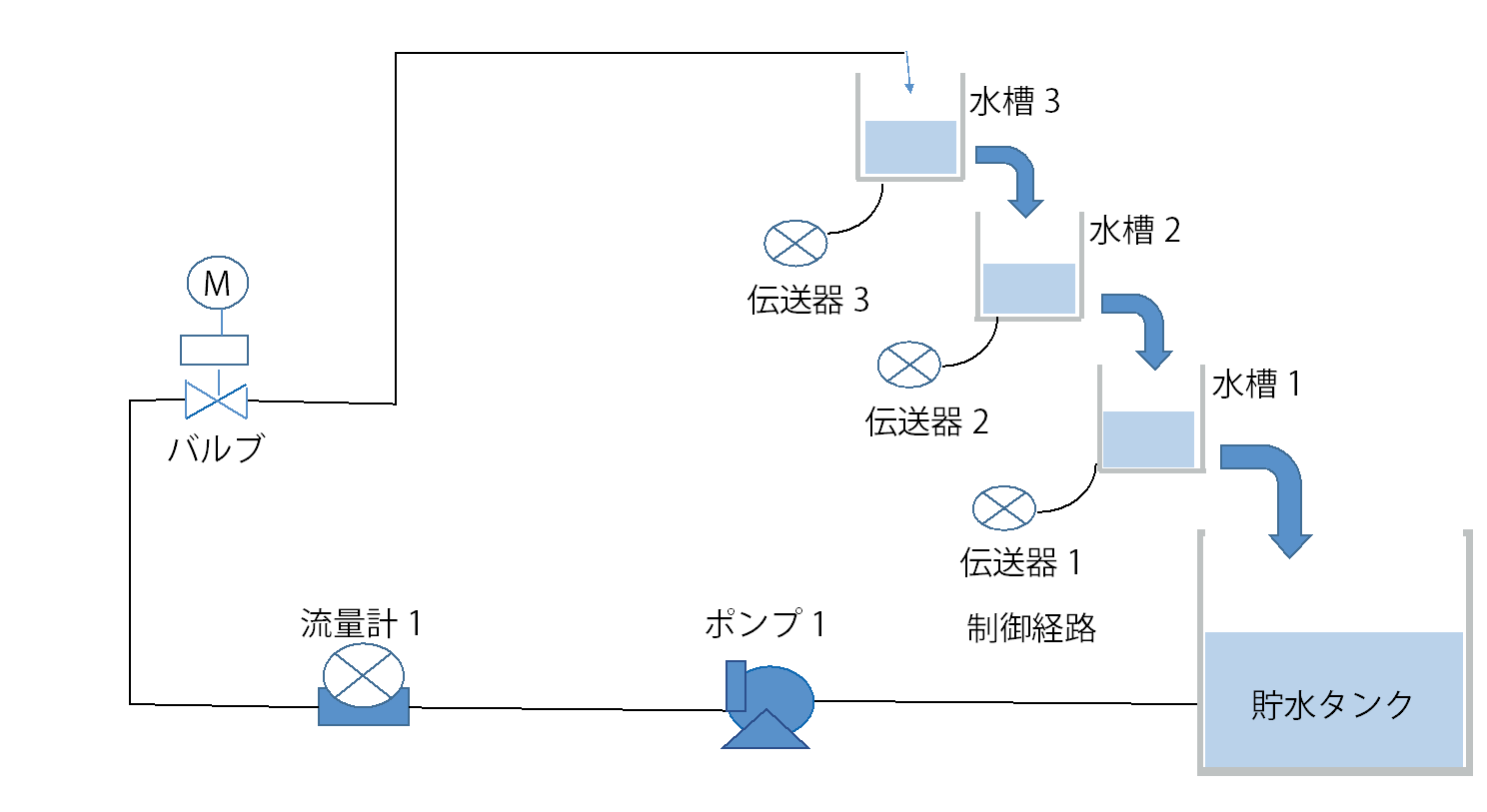
図 1 三段水槽システム図
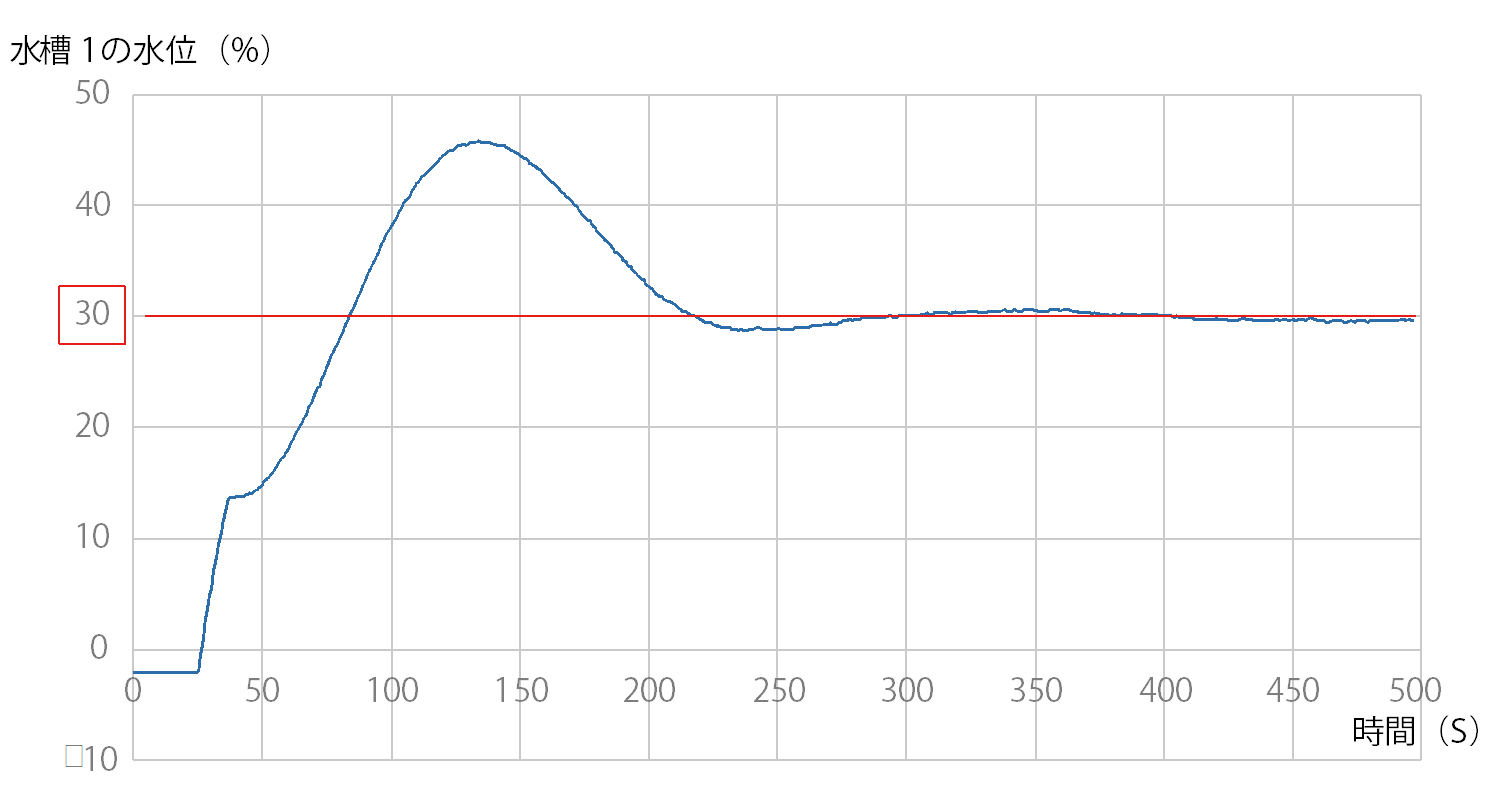
図 2 PID 制御時の水槽 1 の水位
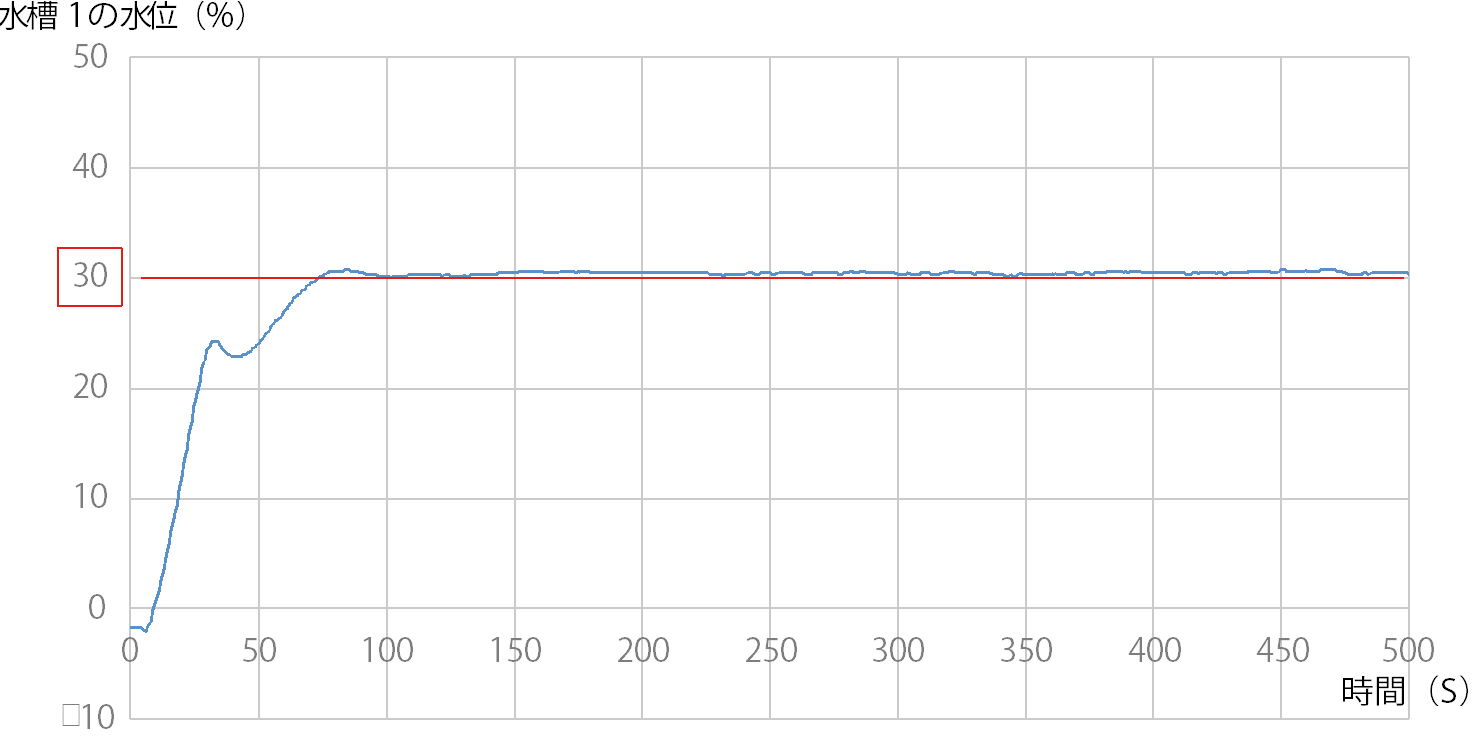
図 3 学習を 30 回終えた後に制御した水位
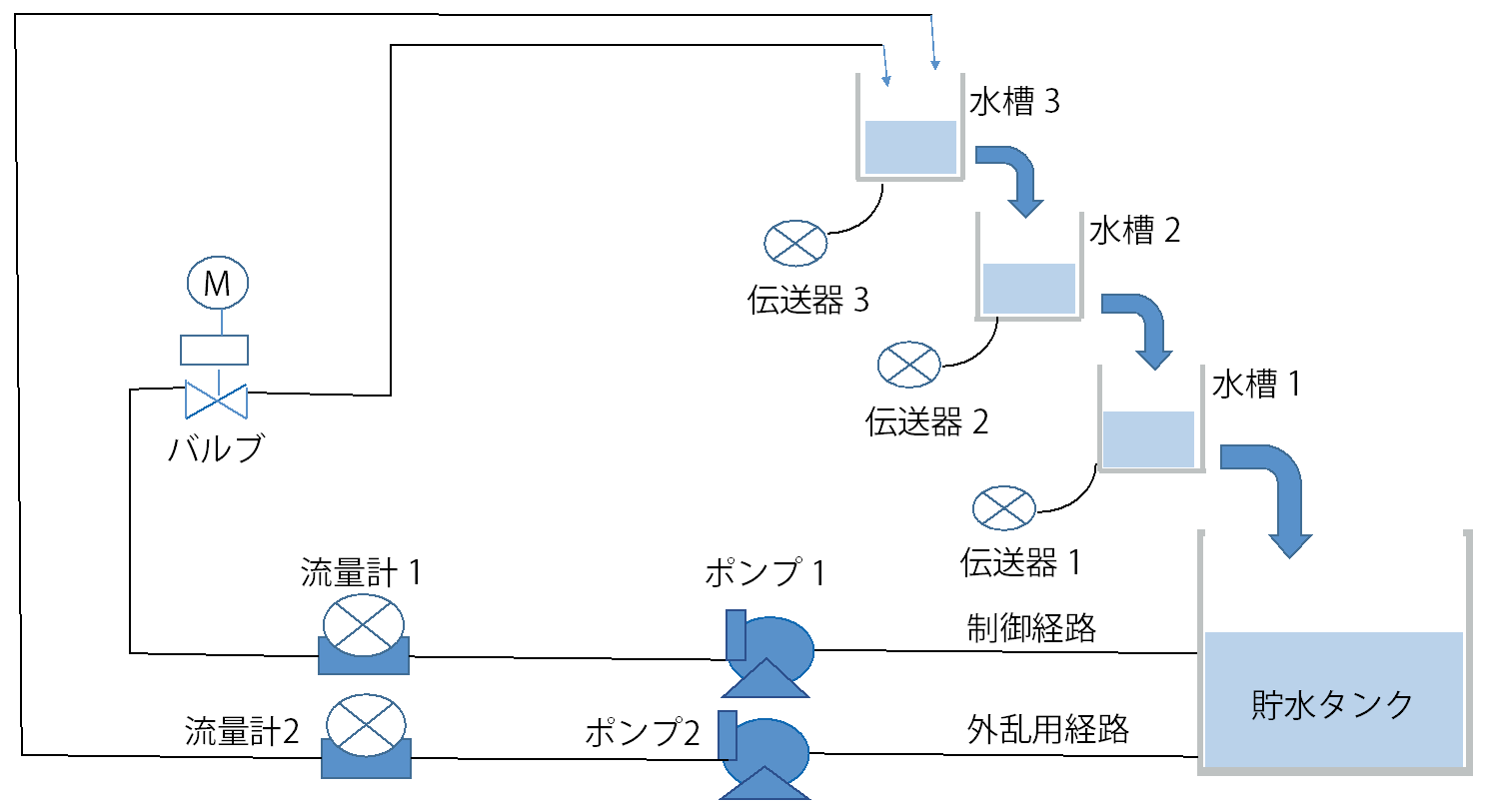
図 4 外乱経路を設定した三段水槽システム図
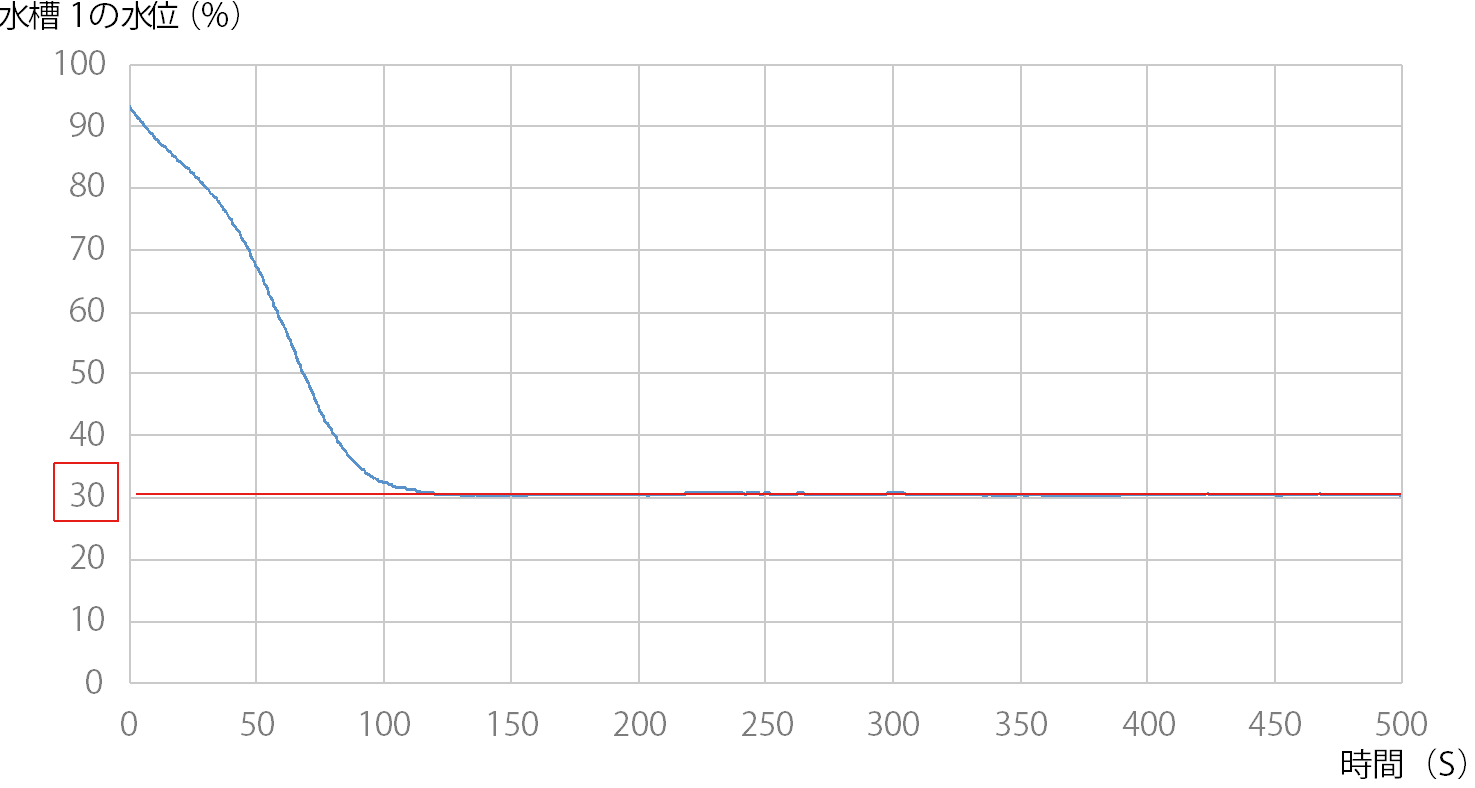
5 水槽 1 の水位を上げた状態でスタート
ポータルサイトへ